
What are GPTs?
Generative Pre-trained Transformers or GPTs for short are a new class of language models that are being used for tailormade text generation using Natural Language Processing (NLP).
The most recent release was GPT 4, a large language model that is capable of generating natural language text that is almost indistinguishable from human-written text.
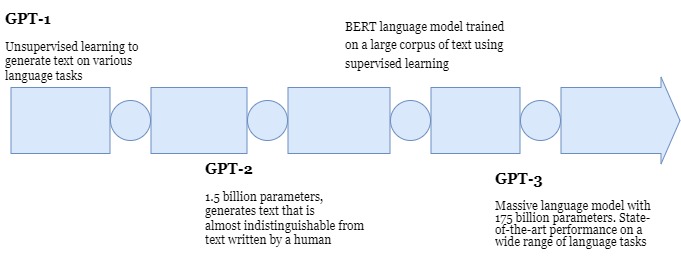
All three models have the same structure and the difference in the number of blocks they have used.
A GPT is a twelve-layer, twelve-attention head transformer decoder which explores and makes use of unlabelled text datasets to fine-tune them on limited supervised learning datasets.
The model architecture makes it so convenient that the first iteration in this series of pre-trained transformers was able to accurately perform question answering on large text corpuses.
GPTs are being used widely nowadays to perform semantic segmentation, text extraction, sentiment classification, text generation, and much more as the days go by.
Model architecture with GPT-1 was able to perform question-answering based on essays. Right now, GPT is used in Semantic segmentation, brain tumor segmentation, and text extraction, sentiment classification datasets, etc and a lot more tasks.
I will explain it to you by Transformer diagram:
Transformer:
GPT is a unidirectional model which only goes forward whereas transformer encoder decoder blocks are used to provide multidirectional facilities. It could travel backward in sentences and predict future words. GPT only predicts the next words.
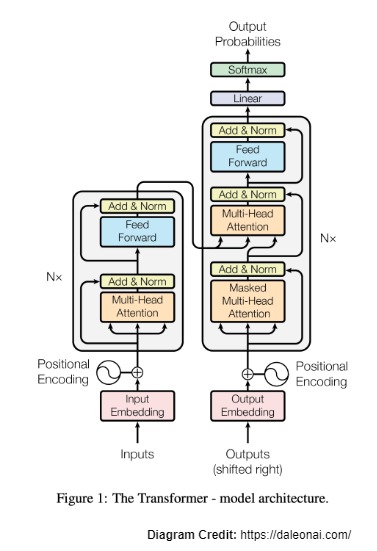
Transformers are a family of neural networks introduced by Google in 2017. It is designed to process sequences of data and was initially meant to perform tasks on textual data but they are also being applied in a variety of other domains of late.
The transformer is composed of an encoder and a decoder. The encoder takes the input sequence and applies a series of self-attention layers to it followed by feedforward layers. The decoder takes the output of the encoder and generates a sequence of output tokens, one token at a time. The decoder also incorporates self-attention and a special attention mechanism that allows it to focus on different parts of the encoder’s output at each step. Attention is nothing but trying to figure out words in the sentences which are focusing on part of the text.
It can handle longer sequences than RNNs making it faster to train on modern hardware. Additionally, the self-attention mechanism allows the model to better capture dependencies between different parts of the input sequences, leading to better performance on a range of NLP tasks.
If you have noticed, ChatGPT is doing one word at a time and predicting the next word and It is doing that by transformer because an output token gets mapped back to words so it has a knowledge base that is how you are getting answers from your ChatGPT.
Advantages with Transformer, RNN had a vanishing gradient problem that means when you ask something at the beginning of the context and you suddenly change at the end, it wouldn’t give you the correct answer and LSTM then introduced to handle this problem but LSTMs has a significant problem where they can’t have handle too much of text. Whereas a Transformer can handle large amounts of text.
Coming up to words split up:
GPTs were created to make use of a semi-supervised learning strategy in Natural Language Processing and would be the first of many models to do this successfully, efficiently, and accurately. Semi-supervised learning is a two-step process where it first trained on large text corpuses unsupervised learning so It was trained on unsupervised datasets with no labels and just texts. After that It is fine-tuned for specific tasks like Q&A, text classification and sequence classification.
Pre-trained:
It’s a second part of GPT which helps with generalization and accuracy. It has been pre-trained with huge datasets.
The pre-training stage of the transformer is done on a large unlabelled text corpus such as BookCorpus datasets(consisting of nearly 11038 books – around 74 million sentences)
Pre-training a model refers to the process of training the model on a large amount of unlabelled data to learn general patterns and representation of the data which would be later used to fine-tune the model.
The Pre-training stage allows the model to learn a vast amount of knowledge about language and the world, which can be fine-tuned for specific tasks such as sentiment analysis, language translation, and question answering.
Generative
Generative which is the first part of GPT is an event to generate new data which resembles input data.It is designed to generate text such that the same text should not be repeated again. It doesn’t maintain the knowledge of what it has generated previously.
If you ask the same question 2-3 minutes later, It would probably give you a different answer. The core solution might be the same but the description before and after might have changed. The generative part of chatGPT is to generate new data every time and generative capability are the result of pre-training.
The Algorithm and working of GPT
Before we deep dive into an algorithm, let me show you some code:
1 2 3 4 5 6 7 | import GPT2Tokenizer, GRP2HeadModel, TextDataset, DataCollatorForLanguageModeling, Trainer, TrainingArguments tokenizer = GPT2Tokenizer.from_pretrained(‘gpt2’); model = GPT2HeadModel.from_pretrained(‘gpt2’); |
GPT does not have an encoder but a transformer does have and the role of the encoder is to convert the text into tokens. There is an explicit module that will convert your text to tokens specifically for GPT. BERT is tokenized for multiple languages but GPT is focused on English only.
1 2 3 4 5 6 7 8 9 10 11 12 13 | import os # define the path to the root directory root_path = 'poemsdataset/forms' # Get a list of all the TXT files in the root directory file_list = [] for dirpath, dirnames, filenames in os.walk(root_path): for filename in filenames: if filename.endswith('.txt'): file_list.append(os.path.join(dirpath, filename)) |
This is the poem dataset which has multiple categories. I just combined all the poems into a text files using helper function.
1 2 3 4 5 6 7 8 | # concatenate all the text data into a single file output_file = 'poemd.txt' with open(output_file, ‘w’) as f: for file_path in file_list: with open(file_path, ‘r’) as f_in: f.write(f_in.read()) |
Above code, poems.txt is the final text file that has all poems in it and uses that in the dataset.
1 2 3 4 5 6 7 8 9 | #create a TextDataset object from the concatenated text dataset = TextDataset( tokenizer=tokenizer, file_path=output_file, block_size=356 ) |
Block size is the number of sequence lengths it can handle.
1 2 3 4 5 6 | data_collator = DataCollatorForLanguageModeling( tokenizer=tokenizer, mlm=false ) |
Now, setting up the model training arguments:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | training_args = TrainingArguments( output_dir='/outputdir', num_train_epochs=10, per_device_train_batch_size=16, per_device_eval_batch_size=32, warmup_steps=500, weight_decay=0.01, logging_dir=’./logs’, logging_steps=100, learning_rate=5e-5 ) trainer = Trainer( model=model, args=training_args, data_collator=data_collator, train_dataset=dataset ) trainer.train() |
And I started training. I have used a pipeline model to help me generate the text. Here is the sample code:
1 2 3 4 5 6 7 8 9 10 11 | import pipeline, GPT2Tokenizer, Automodelwithlmhead tokenizer = GPT2Tokenizer.from_pretrained(‘gpt2’) model = AutoModelWithLMHead.from_pretrained(gpt2_256_full’) poetry_generator = pipeline('text-generation', model=model, tokenizer=tokenizer) prompt = 'Love the Poem' generated_poem = poetry_generator(prompt, max_length=512) |
GPT has been found to work with a minimum context size of at least 27 words. So, It needed at least 27 words to predict the next word.
I have shown the output from GPT-2. I didn’t fine-tune GPT-3 because it is a large language model and I can’t fine-tune the 173 billion parameter model in the demo
Let’s go back to Algorithms.
Pre-training: Large text corpus to enable the model for general usage
Gives an unsupervised corpus of tokens U = {u1, . . . , un}, we use a standard language modeling objective to maximize the following likelihood:
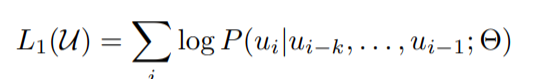
where k is the size of the context window, and the conditional probability P is modeled with the help of a neural network (NN) with parameters Θ. These parameters are trained using stochastic gradient descent [51]
In our experiments, we use a multi-layer Transformer decoder for the language model which is a variant of the transformer [63[. This model applies a multi-headed self-attention operation over the input context tokens followed by position-wise feedforward layers to produce an output distribution over target tokens:
The way GPT works doing unsupervised and supervised prediction at the same time. It becomes a few Shot learning module. GPT aimed to fine-tune all the time but GPT-1 did not do very well. Although GPT-2 was slightly improved and GPT-3 was very much improved. The algorithm remains same for all three variances of GPT.
Supervised Fine-Tuning
After training the model with the objective in Eq. 1, we adapt the parameters to the supervised target task. We assume a labeled dataset C, where each instance consists of a sequence of input tokens, x1, . . . , xm, along with a label y. The inputs are passed through our pre-trained model to obtain the final transformer block’s activation hlm which is then injected into an additional linear output layer parameters Wy to estimate y:

Fine-tuning algorithm where you are trying to predict the probability of the next word given a set of words 1 to m where m is again your context size as an input. From there it is trying to predict the maximum probability of output. Here, hlm is the final decoded block.
GPT does fine-tuning and unsupervised pre-training and try to learn parameters.
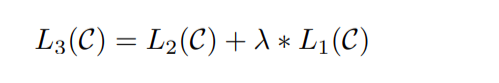
L2(c) is an unsupervised function + lambda L1( c) is a supervised function.
Since the accuracy is still increasing for more blocks, you are limited by Compute. GPT 3 trained using the same architecture but increased the blocks. GPT2 had been trained using byte pair encoding which focused on the English language so GPT 3 suffered from other languages and the compute cost was very large.
Zero Shot Learners:
After training the network on the massive unlabelled dataset of books, it was found that the model was performing other tasks such as sentiment analysis, and question answering also significantly better without any actual individual fine-tuning.
This leads to the conclusion that the GPT model could be a Zero Shot learning model with the capability to perform multiple tasks given the same text corpus. (core concept for the GPT-2 research paper)
Below three are of the main basis for GPT to achieve Zero Shot learning:
Transfer learning: Pre-training model on a used dataset. From unsupervised learning, whatever it has learned, will be fine-tuned, that is called transfer learning.
Domain adaptation: Different domains are being uses it.
Contextual understanding: Providing different types of context to it
GPT-3 is a few Shot learning models so it’s not meant to fine-tune it. If you fine-tune GPT-3, it will be fine-tuned for a custom prompt. GPT accepts pandas, pipeline, and text datasets.
GPT-3
GPT-3, just like GPT was pre-trained but it was able to perform Zero Shot learning tasks without fine-tuning which GPT performed after fine-tuning on supervised datasets such as question answering.
GPT-3 was able to generate better Natural Language Text than its predecessors and is harder to distinguish from the human text.
No change in model architecture – Stack of decoded blocks layered on top of each other. Tokens can only look at themselves and the previously arrived tokens
Datasets used Common Crawl + web text. Common Crawl web crawler crawls through links and browser history and gathers a lot of data from the web.
GPT-3 one shot/few shot approach
One Shot: represents most accurately the way humans work, make predictions with just one sample provided to the model
Few Shot: choose an arbitrary value K in the range 10-100. This represents the number of examples can fit in the model’s context window.
Zero Shot: Zero shot is a very difficult approach to achieving sound results as it may be difficult for the model to understand the format of the task without prior examples. Nevertheless, there are cases such as machine translation where such as approach required
GPT-3 vs ChatGPT
Task focus: ChatGPT is primarily designed for conversational applications while GPT-3 is a more general language model that can be used for a wide range of natural language tasks
Size: ChatGPT is a smaller model than GPT-3 ~ 20 billion parameters. IT is much smaller than GPT-3 which has 175 million parameters
Training data: ChatGPT was trained on a dataset of conversational text while GPT-3 was trained on a variety of sources such as books, crawlers, web texts, links, etc
Applications: ChatGPT is specifically designed for conversational applications, it is better suited for chatbots, virtual assistants, and other similar applications. GPT-3, on the other hand, can be used for a wider range of applications including text generation, language translation, and sentiment analysis.
GPT-4
OpenAI has officially introduced GPT-4, a large multimodal model capable of processing image and text inputs and producing text outputs – the successor to GPT-3 on 14th March 2023
Despite its capabilities, GPT-4 has similar limitations to earlier GPT models, it is not fully reliable, has a limited context window, and does not learn from experience.
GPT-4 has achieved better results in the problem of Natural Language inference and performs significantly better than GPT-3 on examinations as well.
GPT-4 Vision
GPT-4 accepts prompts consisting of both images and text, lets the user specify any vision or language task such as generating captions or creating a joke or an article just from the picture as input
GPT-4 accepts prompts consisting of both images and text, which parallel to the text-only setting. Let the user specify any vision or language task
This feature is not yet open to public access as it is still in the early development stage.
One thing GPT has struggled with is providing facts because the way GPT provides you an answer for facts from a single source and how you know if it’s real or not. GPT-4 has improved factual evaluation.















{kind=link}
Comments (1)