
We talked about GPT/ChatGPT Algorithm in the previous article and basic details about fine-tuning GPT. Today, we will talk about how fine-tuning is important for ChatGPT and how we can simplify it with LangChain.
LangChain is a Python library that helps to build GPT-powered applications in minutes. Chains in LangChain bring together multiple components to create a cohesive application. By combining user input with prompts and interacting with LLM(Large Language Models), chains allow for seamless integration. Using vector DBs, chains can access memory, enhance the capabilities of the application. We will use Vector Databases as memory. Vector databases store embedded text indexes to manage large sets of documents efficiently.
How do we go about fine-tuning?
For GPT-3, data should be in a specific format called “jsonl”. Jsonl is a type of formatting where each key-value pair is separated by a new line instead of commas.
1 2 3 4 | ["k1":"v1"] ["k2":"v2"] and so on |
Data Collection: Collect a large corpus of text data that is relevant to the business problem you are trying to solve. You can obtain data from various sources such as social media, customer reviews, and support tickets. It is recommended to have at least 10000 to 100000 examples to achieve good results.
Data Cleaning: Clean the data to remove any irrelevant or duplicate data. This can include removing HTML tags, URLs, and specific characters. You may also want to remove stop words, unexpected characters, delimiters or other words that don’t add much value to the language model. You can use regular expressions or libraries such as NLTK or SpaCy to perform data cleaning.
Evaluation metrics and Transfer Learning
Perplexity: It measures how well the model predicts the next token in a sequence. Lower perplexity indicates the better model performance.
Accuracy: measures the percentage of correct predictions made by the model.
F1 Score: measures the trade-off between precisions and recall. It is the harmonic mean of precision and recall.
BLEU SCORE: BLEU(BiLingual Evaluation Understudy) SCORE measures the similarity between the generated text and the reference text. It is commonly used for machine translation and text-generation tasks.
Transfer Learning:
It is a normal procedure using the unsupervised model and fine-tuning it. Fine-tuning a pre-trained model such as LLM, or GPT-3 on a custom data set.
- Domain Adaptation
Fine-tuning a pre-trained model on a custom dataset that is similar but not identical to the original pre-training dataset. - Multi-task Learning
Fine-tuning a pre-trained model on multiple tasks simultaneously. This can help improve the model’s ability to generalize to new tasks - Unsupervised Pre-training
Pre-training the model on a large unlabeled dataset before fine tuning on a similar labeled datasets - Semi-Supervised Learning
Training the model on a combination of labeled and unlabeled data
When we do fine-tuning of GPT, it changes the weights of the model for every input prompt but it does not save it. If you have cleaned and saved the weights and you provide a prompt to it and you get the answer. It is changing the weights for that particular prompt to match the answer. However, after that, those weights are no longer saved so it retains the original weights after it’s pre-trained.
If I’ve custom finetuned it and it is in my OpenAI account only and then it will continue to store changed GPT in my account. This way, it changes the instance weights. It does change parameters but not to a great extent. There are 7 billion parameters so it will change affected and learning will be changed to match the task asking for.
In traditional Transfer Learning, We kind of chop off the final one or two or three layers on a baseline on one model and we freeze the initial few layers and retrain the last few layers to learn the custom features.
Here, we are not freezing these layers and it uses base features and create features for our dataset. Transfer Learning is using those that were learned through the unsupervised pre-training method and those features are being used in the semi-supervised learning format on your specific dataset which will be fine-tuned.
Let’s understand this by example code
1 2 3 4 5 6 7 8 9 10 11 12 13 | import transformers import numpy as np import torch import pandas as pd import datasets import matplotlib.pyplot as plt from transformers import GPT2Tokenizer, GPT2LMHeadModel, TextDataset, DataCollatorForLanguageModeling dataframes = pd.read.csv(path_to_csv.csv‘’); dataframes.isna().sum() dataframes.head(); |
The way GPT do expect data it’s in a single column called text. So in that single column, you will have to add everything. Based on that, you can automatically figure out why GPT2 failed in Question-Answering model because you add your entire text in one column. So that It doesn’t have proper National Language Interferences work and it won’t understand what is what and can’t do well.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | dataCollator = DataCollatorForLanguageModeling( tokenizer=tokenizer, mlm_probability: false ); # Create Training Arguments trainingArgs = TrainingArguments( output_dir='./results', # output directory num_train_epochs=10, # total number of training epochs per_device_train_batch_size=10, # batch size per device during training per_device_eval_batch_size=18, # batch size for evaluation warmup_steps=500, # number of warmup steps for learning rate scheduler weight_decay=0.01, # strength of weight decay logging_dir='./logs', # directory for storing logs logging_steps=100, learning_rate:5e-5 ) trainer = Trainer( model:model args:trainingArgs, data_collator=dataCollator, train_dataset=dataset ) model.save_pretrained("path/to/gpt2_full") |
Saved model and loaded it.
1 2 3 4 5 6 7 8 9 10 11 12 13 | from transformer import pipeline, GTP2Tokenizer, AutoModelWithLMHead tokenizer = GTP2Tokenizer.from_pretrained('gpt2') model = AutoModelWithLMHead.from_pretrained(checkpoint); businessGenerator = pipeline('text_generator', model=model, tokenizer=tokenizer) prompt = 'philips refrigerator' generatedText = businessGenerator(prompt, max_length=100) |
Here, used the pipeline to get an answer without knowing the entire dataset. I have passed text in a prompt and it generates output using the values in the dataset and its sort of expected output. GPT2 suffers from basic text generation so it is not a good choice for carrying out Question-answer at the business level. Question-answering is possible but you won’t get accurate answers.GPT2 should not be used in fine-tuning business models because it’s outdated.
Fine-tuning with GPT 3
For GPT-3, there is a set of commands you can execute
1 2 3 4 5 | Openai API completions.create -m curie:ft-cellstrat-2023-04-22 -p "What is total facilities as measured in square feet are leased? ->" –stop=[" <|>"] -> 0.49395 <|> 0.99905 |
Example format,
1 2 3 4 | {"prompt": "<prompt_text>", "completion": "<generated_text>"} {"prompt": "<prompt_text>", "completion": "<generated_text>"} |
This is the format of a dataset being used to fine-tune GPT-3. GPT will be able to give an answer based on different time periods so the above command will give you the answer which uses features learned to generate answers.
Prompt Engineering is a very important task in GPT-3 fine-tuning because magic happens in how you create a Prompt. A prompt is representative of every possible scenario to be answered. So, if you question asked is not in a dataset with matched keywords, it may give you a wrong answer and again you have to rephrase your question and have to ask. If your keyword matches in prompt, it will answer accurately.
Therefore, you have to create a significantly large prompt database to get an accurate answer instead of a relevant one.
Now, Let’s get into the solution to all the problems. So, we will be using LangChain based incorporated model.
LangChain
Here, we will understand how we can make it work with LangChain in Python with large datasets. You can also use LangFlow to create complex prompts in LangChain using user interface instead of writing logic.
Let’s check the LangChain code to explain
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | !pip install langchain !pip install unstructured !pip install openai !pip install pybind11 !pip install chromadb !pip install Cython import od os.environ["OPENAI_API_KEY"] = "INSERT_YOUR_KEY_HERE" from langchain.document_loaders import UnstructuredPDFLoader from langchain.indexes import VectorstoreIndexCreator from detectron2.config import global_cfg cfg = get_cfg() cfg.MODEL.DEVICE = "cpu" #GPU is recommended assetFolder = 'assets' loaders = [UnstructuredPDFLoader(os.path.join(assetFolder, fn)) for fn in os.listdir(assetFolder)] |
Using LangChain and ChromaDB which are the two important modules here. We will be using the LangChain module to create a vector store index so this entire thing is to create vectors to ready the LangChain model to understand that we are going to use the LLM model. Also, using detectron as base model to know the indexes from detectron model. Above code is to read a PDF of a sample report of 120 pages and use pytesseract module to perform OCR to extract text from PDF.
1 2 3 | Apt-get install tesseract-ocr |
Loading document loader from unstructured PDF loader to create PDF loader and In this Loader, there are modules such as tesseract which is doing work behind the scene extracting text and loading it into loader. Now, provided text_folder to be an assets folder that has a PDF file and loaded it to loaders using an unstructured PDF loader.
After that, we need some utilities such as tiktoken and poppler installed using
1 2 3 4 5 6 | apt-get install poppler-utils pip install tiktoken index = VectorstoreIndexCreator().from_loaders(loaders) |
Poppler is required for PDF processing and tiktoken is just a sub-dependency required by indexstore without it won’t run. So after initializing the vector store index, downloaded the models from detectron, and used chromaDB using embedded DuckDB without persistence. So, data will be transient after the session ends.
1 2 3 4 | query = ‘give me summary of doc’; index.query(query); |
NOTE: Detectron has very good limit for input length. It is very large model to perform segmentation and text generation.
LangChain is the best tool for business models because it solves the problem of GPT2 and GPT3. Important point is, it is not exactly fine-tuning anywhere but it is updating ways according to your data and perform the tasks. It is remembering the context out of the box which is best suited for a question-answering model. Overall, In Langchain, you are combining models and updating ways based on your data.
GPT won’t answer even if the information is present but if it doesn’t match the keywords used in the input where LangChain can. LangChain takes care of most of the flows that were there in traditional fine-tuning.
GPT is a decoder-based model and the reason we don’t use transformers for GPT is because transformers learn bi-directional but GPT is uni-directional because the task of GPT is to predict the next word in the sentence. Traditional transformers go back and front, the GPT model just goes front and is able to predict the next word without knowing what is there after it.
Results from fine-tuning GPT-3 vs LangChain
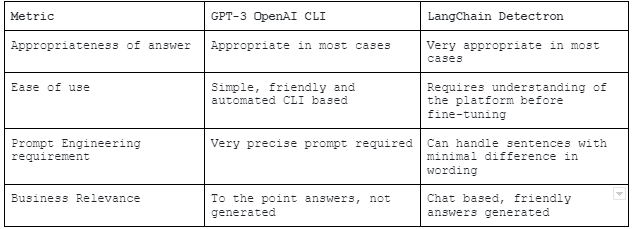
LangChain is an enterprise application integration layer that integrate various models and APIs. A big advantage of LangChain is you don’t even need to extract the text encoded into a model. You can use Excel, word, or PDF documents to extract data.
Conclusion
Employing a model like ChatGPT is highly advantageous when it comes to conversational applications due to its approachable and straightforward way of generating text. It remains focused and avoids producing any unrelated information to the user’s query.
It is true that GPT-3 and GPT-2 are massive language models, but their primary purpose was not geared towards conversational applications. However, in tasks such as Named Entity Recognition and establishing semantic connections between words. GPT-3 surpasses ChatGPT. GPT-2 on the other hand, is losing relevance and is no longer utilized except in situations where low-cost textual generation is sufficient.

















{kind=link}
Comments (1)